机器学习_4:模型实用技巧
只套用模型会造成以下问题:
- 不能保证数据特征都是好的
- 学习得到的参数不一定是最优的
- 默认配置下的模型不是最佳的
因此,本节给出三种提升模型性能的方法
特征提升
特征抽取
将类似于声纹,图像,符号化等文本量化为特征向量。可以用DictVectorizer对特征进行抽取与向量化
# 自定义字典
measurements=[{'city':'Dubai', 'temperature':33},
{'city':'London', 'temperature':12},
{'city':'San', 'temperature':18}]
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
print(vec.fit_transform(measurements).toarray()) # 输出转化后的特征矩阵
print(vec.get_feature_names_out()) # 输出维度含义结果为矩阵,如下所示:

特征筛选
良好的特征不需要太多就能使模型的性能更上一层楼,不良的特征不仅会降低模型的精度,更会浪费cpu的算力去计算。
特征筛选与前文讲过的PCA不同,对于PCA来说,我们经常无法解释重建之后的特征;但是特征筛选不存在对特征值的修改,而更加侧重于寻找那些对模型的性能提升较大的少量特征。
依然以Titanic做例子,如同前文一样做小量处理后直接套入模型,这个例子有一些抽象,也有可能数据本身就已经很完美了,所以不需要删除无用特征
import pandas as pd
data = pd.read_csv('train.csv')
X = data.drop(['Name', 'Survived', 'PassengerId'], axis=1, errors='ignore')
y = data['Survived']
print(X.columns)
# 查看缺失值
X.isnull().sum()
y.isnull().sum()
X['Age'].fillna(X['Age'].mean(), inplace=True)
X.fillna('UNKNOWN', inplace=True)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)
# 对类别特征进行转化,成为特征向量
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False)
X_train = vec.fit_transform(X_train.to_dict(orient='records'))
X_test = vec.transform(X_test.to_dict(orient='records'))
print(len(vec.feature_names_))
# 普通决策树
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion='entropy')
dt.fit(X_train, y_train)
dt.score(X_test, y_test)
from sklearn import feature_selection
# 筛选前20%的特征
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=20)
X_train_fs = fs.fit_transform(X_train, y_train)
dt.fit(X_train_fs, y_train)
X_test_fs = fs.transform(X_test)
dt.score(X_test_fs, y_test)
# 交叉验证
from sklearn.model_selection import cross_val_score
import numpy as np
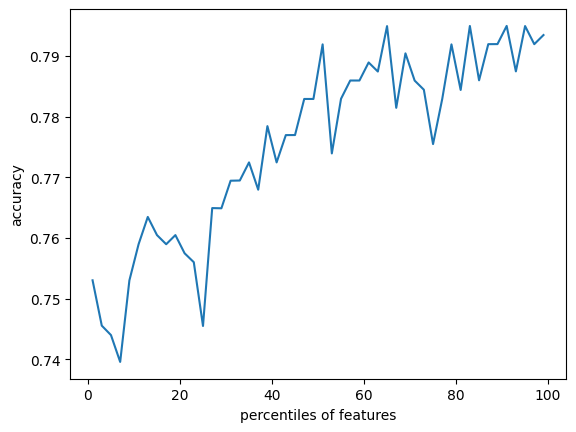
percentiles = range(1, 100, 2)
results = []
for i in percentiles:
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=i)
X_train_fs = fs.fit_transform(X_train, y_train)
scores = cross_val_score(dt, X_train_fs, y_train, cv=5)
results = np.append(results, scores.mean())
print(results)
# 作图
import pylab as pl
pl.plot(percentiles, results)
pl.xlabel('percentiles of features')
pl.ylabel('accuracy')
pl.show()结果如下:
模型正则化
正则化的主要目的是为了提高模型泛化能力
欠拟合与过拟合
顾名思义了,不多赘述了。
L1,L2范数正则化
检验是否存在过拟合或欠拟合现象,可以当做是一种评价指标
模型检验
留一验证
留一验证(Leave-one-out cross validation)最为简单,就是从任务提供的数据中,随机采样一定比例作为训练集,剩下的“留做"验证。通常,我们取这个比例为7:3,即70%作为训练集,剩下的30%用做模型验证。不过,通过这一验证方法优化的模型性能也不稳定,原因在于对验证集合随机采样的不确定性。因此,这一方法被使用在计算能力较弱,而相对数据规模较大的机器学习发展的早期。当我们拥有足够的计算资源之后,这一验证方法进化成为更加高级的版本:交叉验证。
交叉验证
懒的敲了,前面用过了主要是,随便复制粘贴了一哈

超参数搜索
- 网格搜索
- 并行搜索(n_jobs)
- 智能算法