Kaggle比赛:Titanic - Machine Learning from Disaster
链接:https://www.kaggle.com/competitions/titanic
成绩758/15641(2024.4.21):
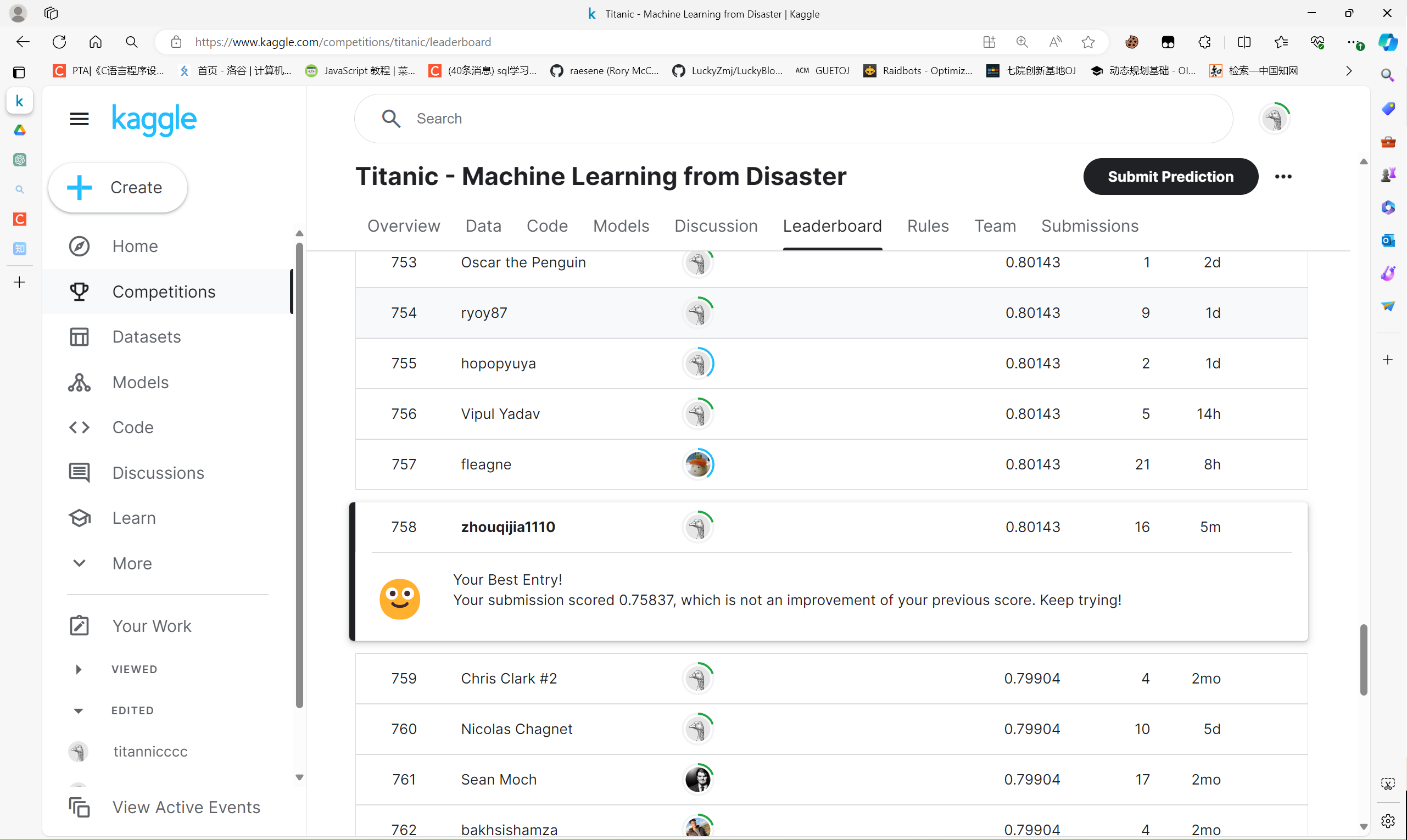
还算不错吧,虽然是学习赛但好歹也是个5%嘻嘻
代码分析及思路
导入包与数据集
所有的包都放在一个代码块了,个人习惯而已
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import scipy.stats as stats
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
from scipy.stats import pointbiserialr
from scipy.stats import chi2_contingency
from sklearn.tree import DecisionTreeRegressor
from sklearn.impute import SimpleImputer
from sklearn.model_selection import GridSearchCVdata_train = pd.read_csv('train.csv')
data_test = pd.read_csv('test.csv')
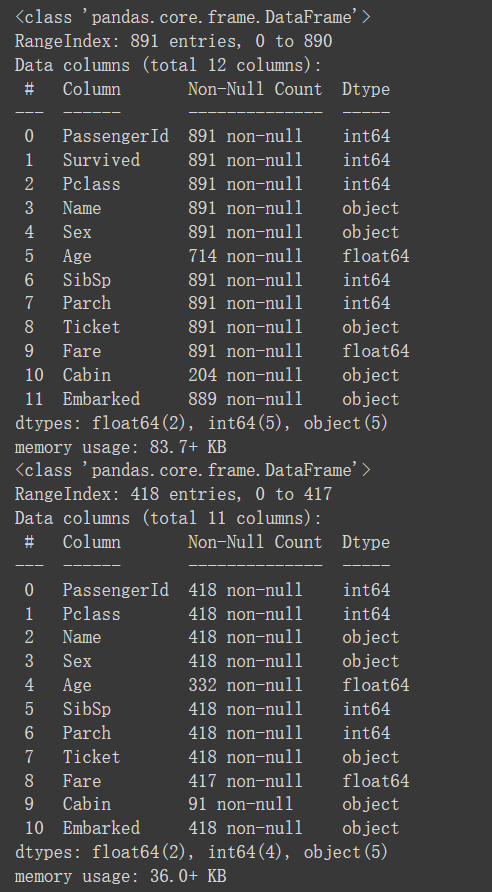
data_train.info()
data_test.info()导入数据,并通过info查看基本信息,describe也可以,还是个人习惯,主要是int和float不太适用于后续的树模型(xgboost)
数据探索
这一块主要是为了做描述性统计的,做一些基础的分析
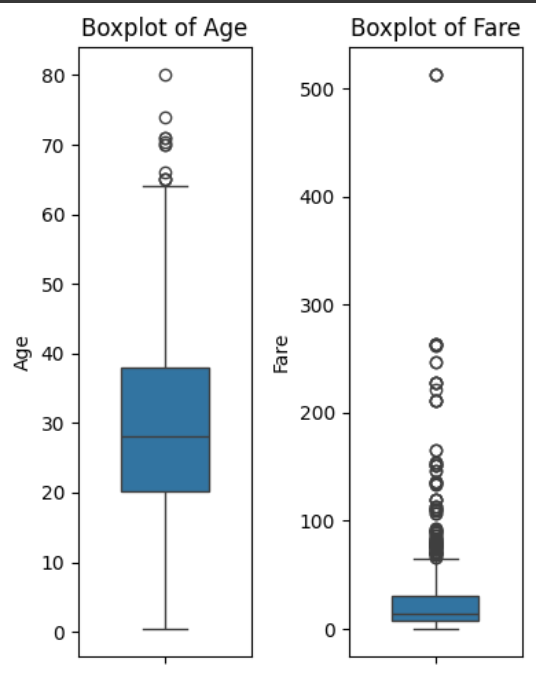
# 连续性变量Age与Fare的箱线图
fig, axes = plt.subplots(1, 2, figsize=(4, 5))
data = data_train
sns.boxplot(data['Age'], orient='v', width=0.5, ax=axes[0])
axes[0].set_title('Boxplot of Age')
axes[0].set_ylabel('Age')
sns.boxplot(data['Fare'], orient='v', width=0.5, ax=axes[1])
axes[1].set_title('Boxplot of Fare')
axes[1].set_ylabel('Fare')
plt.tight_layout()
# 连续性变量Age与Fare的KDE图
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.kdeplot(data=data[data['Survived'] == 0]['Age'], label='Not Survived', shade=True)
sns.kdeplot(data=data[data['Survived'] == 1]['Age'], label='Survived', shade=True)
plt.xlabel('Age')
plt.ylabel('Density')
plt.title('Relationship between Age and Survived')
plt.legend()
plt.subplot(1, 2, 2)
sns.kdeplot(data=data[data['Survived'] == 0]['Fare'], label='Not Survived', shade=True)
sns.kdeplot(data=data[data['Survived'] == 1]['Fare'], label='Survived', shade=True)
plt.xlabel('Fare')
plt.ylabel('Density')
plt.title('Density Plot of Fare by Survival')
plt.legend()
plt.tight_layout()
# 分类变量与Survived的柱状图
plt.figure(figsize=(10, 5))
plt.subplot(2, 3, 1)
sns.countplot(x='Pclass', hue='Survived', data=data)
plt.xlabel('Pclass')
plt.ylabel('Count')
plt.title('Survival by Pclass')
plt.subplot(2, 3, 2)
sns.countplot(x='Sex', hue='Survived', data=data)
plt.xlabel('Sex')
plt.ylabel('Count')
plt.title('Survival by Sex')
plt.subplot(2, 3, 3)
sns.countplot(x='Embarked', hue='Survived', data=data)
plt.xlabel('Embarked')
plt.ylabel('Count')
plt.title('Survival by Embarked')
plt.subplot(2, 3, 4)
sns.countplot(x='SibSp', hue='Survived', data=data)
plt.xlabel('SibSp')
plt.ylabel('Count')
plt.title('Survival by SibSp')
plt.subplot(2, 3, 5)
sns.countplot(x='Parch', hue='Survived', data=data)
plt.xlabel('Parch')
plt.ylabel('Count')
plt.title('Survival by Parch')
plt.subplot(2, 3, 6)
sns.countplot(x='Cabin', hue='Survived', data=data)
plt.xlabel('Cabin')
plt.ylabel('Count')
plt.title('Survival by Cabin')
plt.tight_layout()
plt.show()Survived为二分类变量。需要注意的是,数值型变量分布可以有箱线图表出;对于分类变量可以有KDE表出,如下:
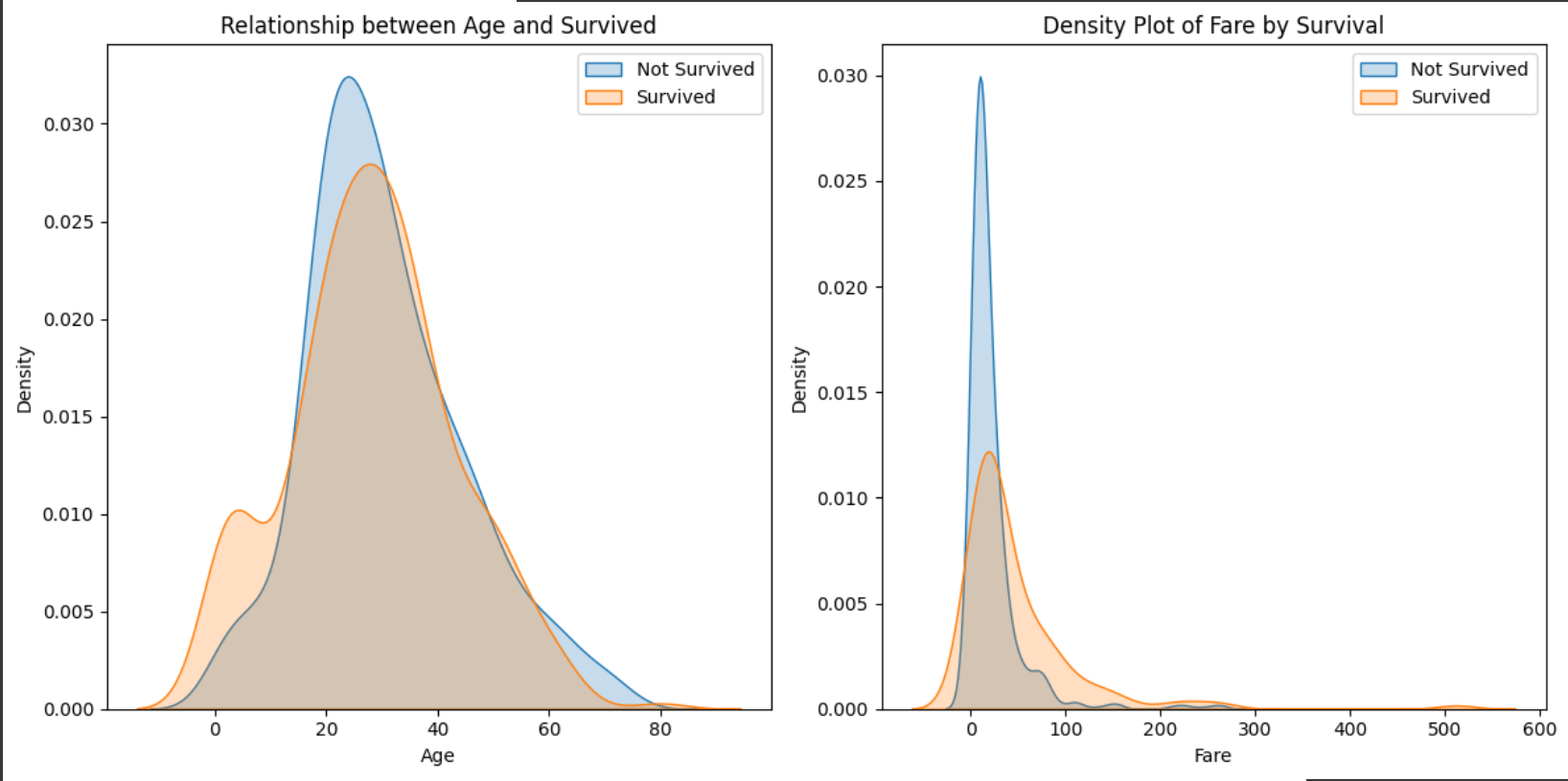
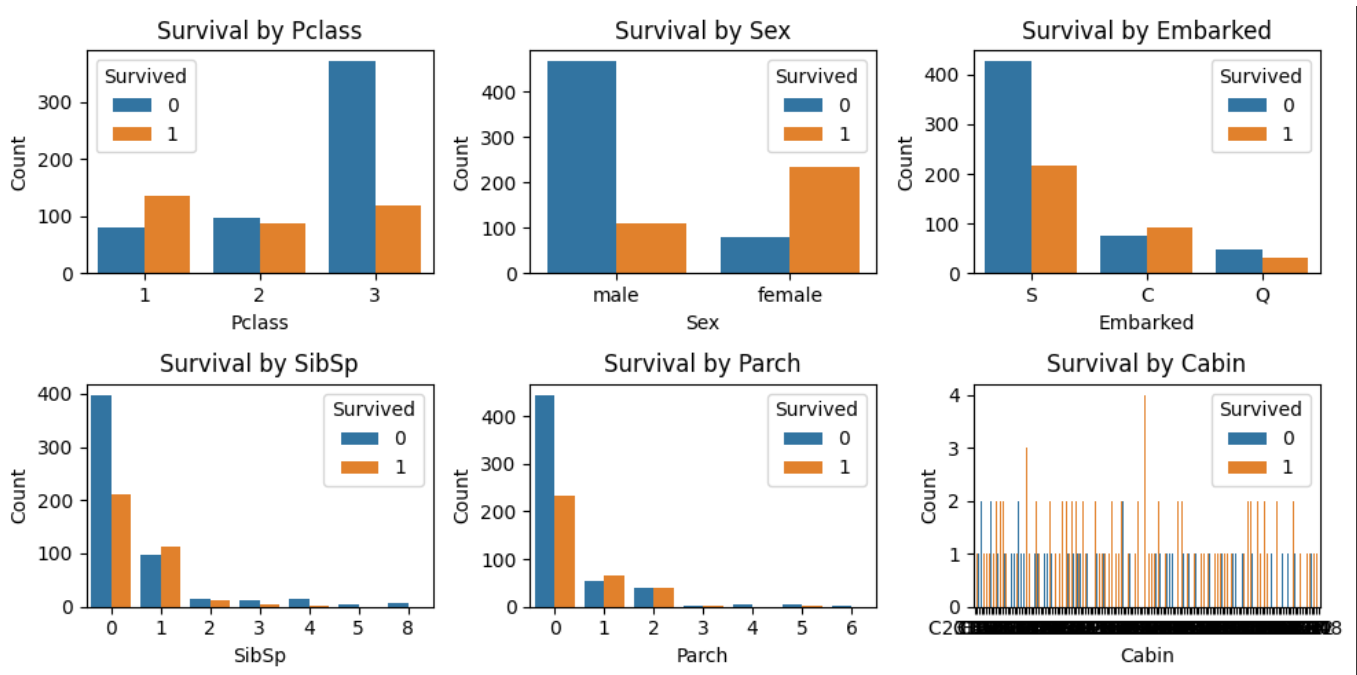
结论可以由上看出,不多说了
最后再查看样本分布数量
# 查看样本量是否平衡
survived_counts = data['Survived'].value_counts()
print(survived_counts)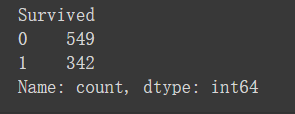
其实是不怎么平衡的,最好在这里使用SMOKE或上采样等方法,这应该是一个上分点
数据挖掘
数据预处理
1. 缺失值处理
train中缺少Age,Cabin与Embraked,test缺少Age,Cabin与Fare。Age,Cabin是大头,其他两个只缺了5个以下所以直接用众数填补(也可以删,但是test需要提交所以不能删)
在此使用模型预测Age(单一决策树)
# 定义一个函数来填补缺失值
def fill_missing_values(df):
# 用平均值填补Fare的缺失值
fare_imputer = SimpleImputer(strategy='mean')
df['Fare'] = fare_imputer.fit_transform(df[['Fare']])
# 用众数填补Embarked的缺失值
embarked_imputer = SimpleImputer(strategy='most_frequent')
df['Embarked'] = embarked_imputer.fit_transform(df[['Embarked']])
# 提取有年龄信息和缺失年龄信息的数据
known_age = df[df['Age'].notna()]
unknown_age = df[df['Age'].isna()]
# 特征和目标变量
X_train = known_age.drop(['Age'], axis=1)
y_train = known_age['Age']
X_test = unknown_age.drop(['Age'], axis=1)
# 训练决策树模型
dt_regressor = DecisionTreeRegressor(random_state=42)
dt_regressor.fit(X_train, y_train)
# 预测缺失值
predicted_age = dt_regressor.predict(X_test)
# 创建一个新的DataFrame来保存填充后的数据
filled_df = df.copy()
# 将预测值填充到新的DataFrame中
filled_df.loc[filled_df['Age'].isna(), 'Age'] = predicted_age
return filled_df如果使用xgboost的话,是不怎么需要处理异常值与缺失值的,但是后文还有其他工程,因此先处理。这种办法的问题就在于需要让自己模型预测值的准确率高,不然就是瞎填补
对于Cabin来说,由于缺失值太多,这里处理为:有值的为1,没值的为0
data['Cabin'] = data['Cabin'].notna().astype(int)
test_data['Cabin'] = test_data['Cabin'].notna().astype(int)注意一个点,修改的时候必须训练集与测试集一起修改。不然模型是预测不了特征个数不对的对应文件的。后文不再赘述
2. 异常值处理
懒的搞了,相信xgboost
3. SibSp与Parch
在此选择相加,但是普通的相加减在树模型中是无效的(加不加对模型的精度都没有提升)。
data['Numbers'] = data['SibSp'] + data['Parch']
data = data.drop(['SibSp', 'Parch'], axis=1)
test_data['Numbers'] = test_data['SibSp'] + test_data['Parch']
test_data = test_data.drop(['SibSp', 'Parch'], axis=1)4. Embarked
在此将其转为1,2,3变量
data['Embarked'] = data['Embarked'].replace({'S':1, 'C':2, 'Q':3})
test_data['Embarked'] = test_data['Embarked'].replace({'S':1, 'C':2, 'Q':3})5. Ticket
我不会处理,对于文本类的真的不是很熟悉,在此我直接删掉这个特征了(别学我)
data = data_train.drop(['Ticket'], axis=1)
test_data = data_test.drop(['Ticket'], axis=1)特征工程
1. 对Name处理
在此借用讨论区大神的办法,我直接删掉,但是大神说通过前缀可以看出这个人的社会地位,因此做整合
# 训练集
data['Title'] = data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
data['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'],'Officer', inplace=True)
data['Title'].replace(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty', inplace=True)
data['Title'].replace(['Mme', 'Ms', 'Mrs'],'Mrs', inplace=True)
data['Title'].replace(['Mlle', 'Miss'], 'Miss', inplace=True)
data['Title'].replace(['Master','Jonkheer'],'Master', inplace=True)
data['Title'].replace(['Mr'], 'Mr', inplace=True)
data = pd.get_dummies(data, columns=['Title'], prefix='Title')
data = data.drop(['Name'], axis=1)
# 测试集
test_data['Title'] = test_data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
test_data['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'],'Officer', inplace=True)
test_data['Title'].replace(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty', inplace=True)
test_data['Title'].replace(['Mme', 'Ms', 'Mrs'],'Mrs', inplace=True)
test_data['Title'].replace(['Mlle', 'Miss'], 'Miss', inplace=True)
test_data['Title'].replace(['Master','Jonkheer'],'Master', inplace=True)
test_data['Title'].replace(['Mr'], 'Mr', inplace=True)
test_data = pd.get_dummies(test_data, columns=['Title'], prefix='Title')
test_data = test_data.drop(['Name'], axis=1)2. 分箱操作
将Age和Numbers进行分箱,模型可以捕捉其中的非线性关系(需要先画qq图观察);Age的异常值过多,分区间后可以使数据更加稠密,降低异常值的影响
首先观察原始分布,为自定义边界做准备
plt.figure(figsize=(8, 6))
sns.kdeplot(data=data[data['Survived'] == 0]['Age'], color='blue', label='Not Survived', shade=True)
sns.kdeplot(data=data[data['Survived'] == 1]['Age'], color='orange', label='Survived', shade=True)
plt.title('Density Distribution of Fare by Survival')
plt.xlabel('Age')
plt.ylabel('Density')
plt.legend()
plt.grid(True)
plt.show()
cross_tab = pd.crosstab(data['Age'], data['Survived'])
cross_tab如下图所示结果,Numbers也是一样的,不做演示了
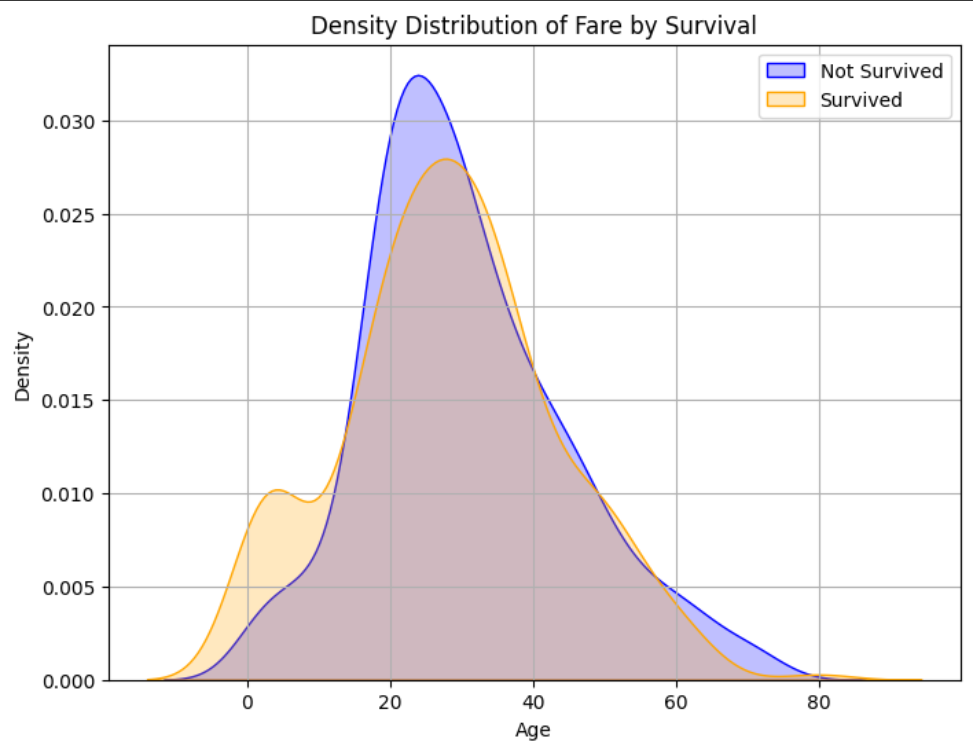
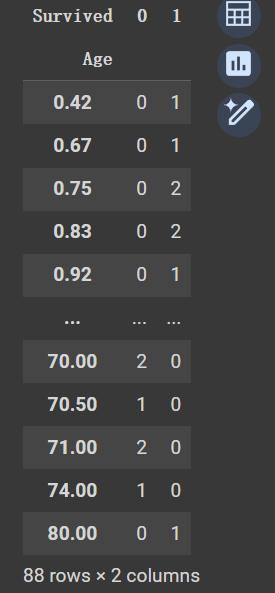
这样就可以明确分组边界了
# 定义分组边界
bins = [0, 5, 18, 30, 40, 50, 80]
labels = ['Age_0_5', 'Age_5_18', 'Age_18_30', 'Age_30_40', 'Age_40_50', 'Age_50_80']
# 对年龄进行分组
data['Age_Group'] = pd.cut(data['Age'], bins=bins, labels=labels)
data = pd.get_dummies(data, columns=['Age_Group'], prefix='Age_Group')
data = data.drop(['Age'], axis=1)
test_data['Age_Group'] = pd.cut(test_data['Age'], bins=bins, labels=labels)
test_data = pd.get_dummies(test_data, columns=['Age_Group'], prefix='Age_Group')
test_data = test_data.drop(['Age'], axis=1)
# 定义分组边界
bins = [0, 1, 2, 3, 10]
labels = ['Age_0_1', 'Age_1_2', 'Age_2_3', 'Age_3_10']
# 对人数进行分组
data['Numbers_Group'] = pd.cut(data['Numbers'], bins=bins, labels=labels)
data = pd.get_dummies(data, columns=['Numbers_Group'], prefix='Numbers')
data = data.drop(['Numbers'], axis=1)
test_data['Numbers_Group'] = pd.cut(test_data['Numbers'], bins=bins, labels=labels)
test_data = pd.get_dummies(test_data, columns=['Numbers_Group'], prefix='Numbers')
test_data = test_data.drop(['Numbers'], axis=1)分组边界都是自己画描述性统计自己分的。其实还有一个Fare作为连续性变量也需要分,但是我分出来之后发现精度反而变滴了,期待有人可以帮我解决疑惑
3. 哑变量处理
将Sex,Embarked分类特征转化为哑变量,有一个疑问是:Embarked按理说应该做哑变量处理,但是我转为1,2,3这样int型反而精更好。不明白为啥
data = pd.get_dummies(data, columns=['Sex'], prefix='Sex')
data['Embarked'] = data['Embarked'].replace({'S':1, 'C':2, 'Q':3})
test_data = pd.get_dummies(test_data, columns=['Sex'], prefix='Sex')
test_data['Embarked'] = test_data['Embarked'].replace({'S':1, 'C':2, 'Q':3})模型
本文使用XGBoost,这个世界上最tmd好用的树模型!!!
1. 预测与保存
# 将数据拆分为特征和目标变量
X = data.drop(['Survived'], axis=1)
y = data['Survived']
# 将数据拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.dtypes)
# 训练XGBoost模型
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 使用训练好的模型进行预测
test_predictions = model.predict(test_data)
# 创建包含PassengerId和Survived字段的DataFrame
results = pd.DataFrame({'PassengerId': test_data['PassengerId'], 'Survived': test_predictions})
# 将结果保存为CSV文件
results.to_csv('result.csv', index=False)其实还有模型调参的部分,但是我调参之后精度反而下降了不少,不懂这是啥原因,可能是做的过于简单了
2. 模型评估
F1,精确率,准确率,召回率和混淆矩阵进行评估
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:")
print(conf_matrix)
precision = precision_score(y_test, y_pred)
print("精确率:", precision)
recall = recall_score(y_test, y_pred)
print("召回率:", recall)
f1 = f1_score(y_test, y_pred)
print("F1指标:", f1)还有一个点,针对树模型可以画出基尼指数做判断,代码与运行结果如下:
# 获取特征重要性得分
feature_importance = model.feature_importances_
# 创建特征重要性的DataFrame
feature_importance_df = pd.DataFrame({'Feature': X_train.columns, 'Importance': feature_importance})
# 按重要性降序排序
feature_importance_df = feature_importance_df.sort_values(by='Importance', ascending=False)
# 可视化特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=feature_importance_df)
plt.title('Feature Importance')
plt.xlabel('Importance Score')
plt.ylabel('Features')
plt.show()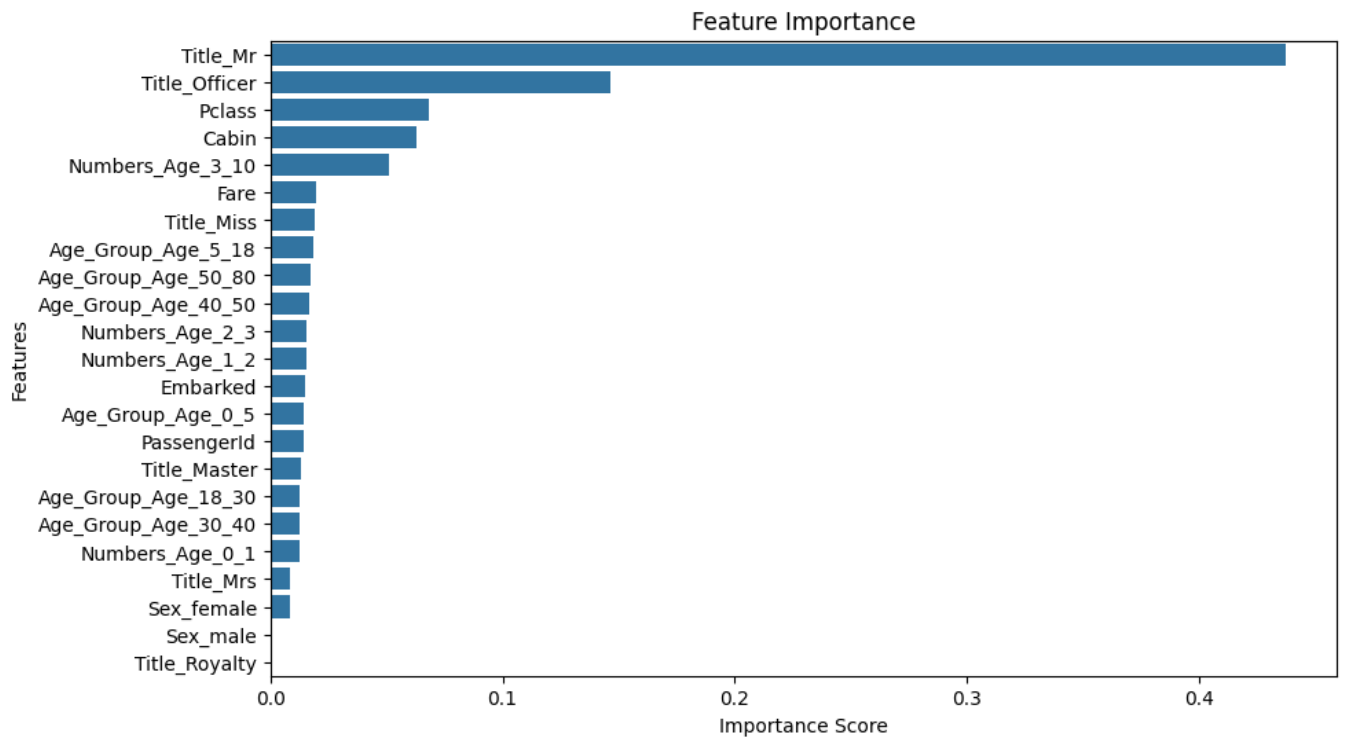
交叉验证
我只能说,你永远可以相信你在本地交叉验证的结果!!!
我自己的精确度为0.83240,提交后的为0.80143,有点过拟合吧?但是交叉验证出来的值非常对,达到了惊人的0.80035。
from sklearn.model_selection import cross_val_score
# 将数据拆分为特征和目标变量
X = data.drop(['Survived'], axis=1)
y = data['Survived']
# 训练XGBoost模型并进行交叉验证
model = xgb.XGBClassifier()
scores = cross_val_score(model, X, y, cv=5) # 使用5折交叉验证
# 输出交叉验证得分
print("交叉验证得分:", scores)
print("平均交叉验证得分:", scores.mean())总结
- XGBoost真的很好用
- 分箱操作很重要
- 千万不要删特征,要做特征工程的转换
- 最后一定要用到交叉分析
改进与疑惑
上分点
- 模型的调参
- Fare的分组
- 对Ticket的处理
- 异常值分类处理
疑惑
- 按理说Embarked应该转为哑变量啊,但是数值型变量反而提升了进度
- 模型调参不对,下次再试试看
- Fare的分箱处理,我没处理好不知道是为啥
- PassengerID按理说没啥用,但是去掉之后又下降了,不理解