机器学习_2:监督学习经典模型
模型是小,因为通过百度掉包都可以实现,但是重要的是流程
分类学习
线性分类器
数据集url地址(乳腺癌良恶性预测):https://archive. ics. uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
假设特征与分类结果存在线性关系,可以累加计算每个维度的特征与各自权重的乘积来帮助类别决策
进行最最最最简单的数据预处理工作(这章主要为了模型)
- 导包
import pandas as pd
import numpy as np- 加载数据
# data数据不存在列名,需手动添加
column_names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size', 'Bare Nuclei', 'Bland chromatin', 'Normal Nucleoli', 'Mitoses', 'class']
data = pd.read_csv('breast-cancer-wisconsin.data', names = column_names) # 读取data
print(data.head()) # 打印前五行查看是否发生问题- 数据预处理部分
data = data.replace(to_replace='?', value=np.nan) # 将缺失值用Null表示
data = data.dropna(how='any') # 只要该维度有缺失,删除
data.shape # 第一个为数据量,第二个为维度- 分隔数据集
from sklearn.model_selection import train_test_split
# 四个参数分别代表:x的特征(前十个),y的特征(第11个),分割大小(1:4),随机种子(可复现)
X_train, X_test, y_train, y_test = train_test_split(data[column_names[1:10]], data[column_names[10]], test_size=0.25, random_state=33)
# 查看数据
print(y_train.value_counts())
print(y_test.value_counts())结果如下:
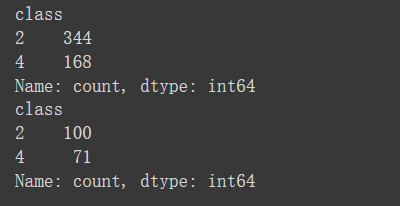
说明y=2的数据有xxx个
- 使用模型
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import SGDClassifier
# 标准化(使其方差为1,不被维度过大的特征主导)
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.fit_transform(X_test)
# 模型初始化
lr = LogisticRegression()
sgdc = SGDClassifier()
lr.fit(X_train, y_train) # 该函数用于训练
lr_y_predict = lr.predict(X_test)
sgdc.fit(X_train, y_train)
sgdc_y_predict = sgdc.predict(X_test)训练两个模型,接着可以进行模型的比较
- 模型性能评估
通过准确率,召回率,精确率和F1指标
混淆矩阵也挺重要的,但是一般自己看就行了
from sklearn.metrics import classification_report
# 自带评分函数,查看准确性结果
print('准确性性能:', lr.score(X_test, y_test))
# 查看其它三个指标结果
print(classification_report(y_test, lr_y_predict, target_names=['Benign', 'Malignant']))
print('准确性性能:', sgdc.score(X_test, y_test))
print(classification_report(y_test, sgdc_y_predict, target_names=['Benign', 'Malignant']))支持向量机(SVM)
KNN
代码大同小异,但是在导入包的时候需要注意查看数据类型,这是一个好习惯
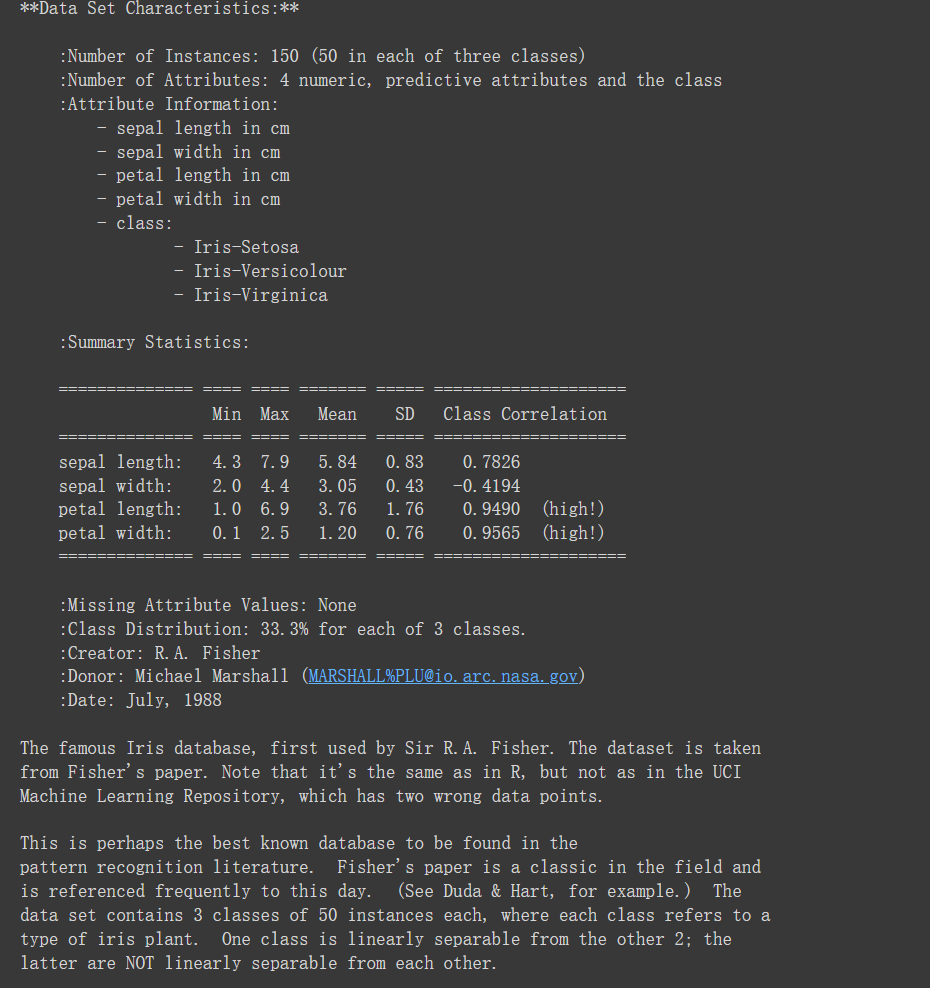
from sklearn.datasets import load_iris
iris = load_iris()
# 查验数据规模
iris.data.shape
# 查看数据说明
print(iris.DESCR)结果如下所示:
单一决策树与集成模型
集成模型,即同时搭建多个独立的分类模型,通过投票的方式少数服从多数。例如随机森林;还有一种是按一定次序搭建多个分类模型(存在依赖关系),后者为前者做贡献,跟新性能为主。例如梯度提升决策树
数据来源:kaggle泰坦尼克号Titanic - Machine Learning from Disaster | Kaggle
import pandas as pd
data = pd.read_csv('train.csv')
X = data[['Pclass', 'Age', 'Sex']]
y = data['Survived']
# 查看缺失值
X.isnull().sum()
y.isnull().sum()
# 用平均数代替(模型为主,数据处理不复杂化),后者参数为就地修改,而不是新建一个df
X['Age'].fillna(X['Age'].mean(), inplace=True)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)
# 对类别特征进行转化,成为特征向量
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False)
X_train = vec.fit_transform(X_train.to_dict(orient='records'))
X_test = vec.transform(X_test.to_dict(orient='records'))
# 单一决策树
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
dtc_y_pred = dtc.predict(X_test)
# 随机森林
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
rfc_y_pred = rfc.predict(X_test)
# 梯度提升决策树
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier()
gbc.fit(X_train, y_train)
gbc_y_pred = gbc.predict(X_test)
from sklearn.metrics import classification_report
print('单一决策树准确率:', dtc.score(X_test, y_test))
print(classification_report(dtc_y_pred, y_test))
print('随机森林树准确率:', rfc.score(X_test, y_test))
print(classification_report(rfc_y_pred, y_test))
print('梯度提升决策树准确率:', gbc.score(X_test, y_test))
print(classification_report(gbc_y_pred, y_test))回归预测
相较于分类而言,回归最大的区别在于预测的目标为连续变量(价格,降雨量等)
线性回归器
以波士顿地区房价为数据集
- 导入数据集(zzzq问题被封了,自己找了一个)
import numpy as np
import pandas as pd
boston = pd.read_csv('boston.csv')
print(boston.head)
X = boston.iloc[:, 0:13] # 选择第 1 到 13 列作为特征 X
y = boston.iloc[:, 13] # 选择第 14 列作为目标变量 Y- 分隔数据集并进行预处理,发现相差过大,需要进行标准化处理
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)
print("最大房价:", np.max(y))
print("最小房价:", np.min(y))
print("平均房价:", np.mean(y))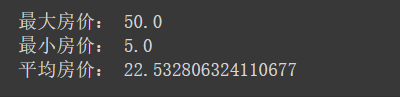
- 标准化处理
这里有一些问题,由于是自己找的数据集,ss必须是二维数据而y为pd的srious数组,因此需要先进行转化
from sklearn.preprocessing import StandardScaler
y_train = y_train.reshape(-1, 1)
ss_X = StandardScaler()
ss_y = StandardScaler()
X_train = ss_X.fit_transform(X_train)
X_test = ss_X.fit_transform(X_test)
y_train = ss_y.fit_transform(y_train)
y_test = ss_y.fit_transform(y_test)- 模型求解
from sklearn.linear_model import LinearRegression
# 线性回归器
lr = LinearRegression()
lr.fit(X_train, y_train)
lr_y_predict = lr.predict(X_test)
from sklearn.linear_model import SGDRegressor
sgdr = SGDRegressor()
sgdr.fit(X_train, y_train)
sgdr_y_predict = sgdr.predict(X_test)- 模型性能
回归和分类不同,此处需要用到MES,MAE和R2
from sklearn.linear_model import LinearRegression
# 线性回归器
lr = LinearRegression()
lr.fit(X_train, y_train)
lr_y_predict = lr.predict(X_test)
from sklearn.linear_model import SGDRegressor
sgdr = SGDRegressor()
sgdr.fit(X_train, y_train)
sgdr_y_predict = sgdr.predict(X_test)
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
print("默认误差:", lr.score(X_test, y_test))
print("R2误差:", r2_score(y_test, lr_y_predict))
print("均方误差:", mean_squared_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(lr_y_predict)))
print("绝对误差:", mean_absolute_error(ss_y.inverse_transform(y_test), ss_y.inverse_transform(lr_y_predict)))回归树
特点分析:在系统地介绍了决策(分类)树与回归树之后,可以总结这类树模型的优点:
①树模型可以解决非线性特征的问题;
②树模型不要求对特征标准化和统一量化,即数值型和类别型特征都可以直接被应用在树模型的构建和预测过程中;
③因为上述原因,树模型也可以直观地输出决策过程,使得预测结果具有可解释性。
同时,树模型也有一些显著的缺陷:
①正是因为树模型可以解决复杂的非线性拟合问题,所以更加容易因为模型搭建过于复杂而丧失对新数据预测的精度(泛化力);
②树模型从上至下的预测流程会因为数据细微的更改而发生较大的结构变化,因此预测稳定性较差;
③依托训练数据构建最佳的树模型是NP难问题,即在有限时间内无法找到最优解的问题,因此我们所使用类似贪婪算法的解法只能找到一些次优解,这也是为什么我们经常借助集成模型,在多个次优解中寻觅更高的模型性能。
模型使用
这一块也就图一乐,反正是官网给的