代码路径:https://github.com/zqqqqqqj1110/CityLearn_exp.git
target
比较不同任务配置下,RBC(Rule-Based Control)与 RLC(Reinforcement Learning Control)在能源、排放、峰值与舒适度方面的表现。
数量: 共 17 个任务(单建筑、多建筑、单目标、多目标)
输出指标:
- Electricity Cost [$]
- Emissions [kg CO₂]
- Peak Demand [kW]
- Discomfort Penalty [–]
准备环境
创建环境,准备citylearn的conda env
conda create -n citylearn python=3.10 -y
conda activate citylearn安装city learn V2
git clone https://github.com/intelligent-environments-lab/CityLearn.git
cd CityLearn
pip install -e . # 源码控制版,仅用于复现
pip install citylearn # 后续试验可以直接用这个下载如果是macOS,pip install的时候会发生如下报错:
ERROR: Ignored the following versions that require a different python version: 2.3.0 Requires-Python >=3.11; 2.3.1 Requires-Python >=3.11; 2.3.2 Requires-Python >=3.11; 2.3.3 Requires-Python >=3.11; 2.3.4 Requires-Python >=3.11
ERROR: Could not find a version that satisfies the requirement openstudio<=3.3.0 (from citylearn) (from versions: 3.5.0, 3.5.1, 3.6.0, 3.6.1, 3.7.0rc1, 3.7.0, 3.8.0, 3.9.0, 3.10.0rc5, 3.10.0)
ERROR: No matching distribution found for openstudio<=3.3.0这是因为OpenStudio 只支持 x86 架构,Apple Silicon (arm64) 下没有编译版本,跳过依赖,自己手动安装
pip install -e . --no-deps
pip install numpy==1.26.4 pandas pyyaml scikit-learn==1.2.2 simplejson torch torchvision gymnasium==0.28.1 nrel-pysam doe_xstock这边建议还是用linux比较好,后续复现都基于Linux而非macOS,macOS的环境配置等我有空了再写(毕竟本地运行最方便)
目前macOS失败的原因:OpenStudio 不支持 macOS ARM 架构
进行测试
配置完环境之后,可以使用测试代码看看效果
from citylearn.citylearn import CityLearnEnv
from pathlib import Path
import numpy as np
# 加载 CityLearn 环境
schema = Path('/root/CityLearn/data/datasets/citylearn_challenge_2021/schema.json')
env = CityLearnEnv(schema=schema)
print("✅ Env loaded successfully!")
# 重置环境(Gymnasium 风格)
obs, info = env.reset()
# 打印建筑数量与ID
print("✅ Number of buildings:", len(env.buildings))
# 打印每栋建筑的观测长度
obs_lens = [len(o) for o in obs]
print("✅ Observation lengths per building:", obs_lens)
# 示例:查看第一个建筑的前5个特征
print("✅ Sample observation (Building 1):", obs[0][:5])
# 如果要转换为矩阵,可以先对齐长度(取最短长度或补零)
min_len = min(obs_lens)
obs_array = np.array([o[:min_len] for o in obs])
print("✅ Converted obs array shape:", obs_array.shape)有五个✅就ok了,输出结果应该如下:
(citylearnv2) root@autodl-container-491e4b9a34-9e5b11d5:~/CityLearn# python Untitled1.py
Couldn't import dot_parser, loading of dot files will not be possible.
✅ Env loaded successfully!
✅ Number of buildings: 9
✅ Observation lengths per building: [28, 27, 26, 27, 28, 28, 27, 27, 27]
✅ Sample observation (Building 1): [1, 4, 1, 9.4, 10.020000457763672]
✅ Converted obs array shape: (9, 26)number of buildings 可以理解为agent的数量,每一个agent都是一个独立的智能体,共享天气、电价、碳排放等全局信息,共同学习协调策略
Observation lengths per building是每个agent的特征数量,这些特征可以是
当前电价,CO₂ 强度,当前时刻,设备能耗(DHW、TES、Battery) 等
Sample observation把一栋建筑的特征编码成一个一维数组,具体含义取决于schema的配置(observations字段),如下所示:
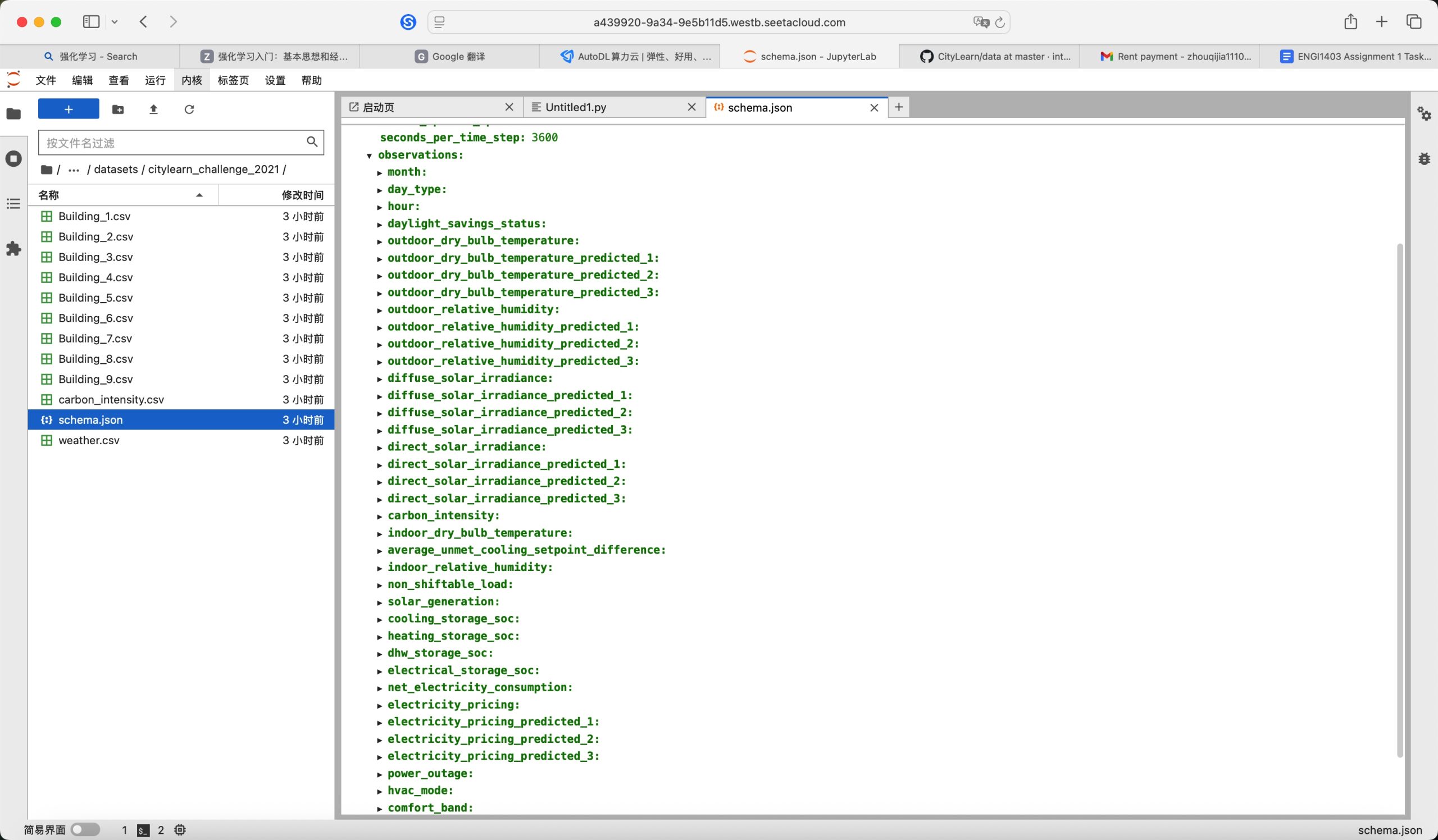
Converted obs array shape是传入到模型的数组,是一个大整体,用于训练
Control task distribution
| 该章节设计了 17 个不同的控制任务,对比 3 种控制方式 + 4 种控制目标。三种方法在代码中的本质区别就是reward不同,需要在传入 CityLearnEnv() 时,自定义Reward Function | 控制器 | 简介 | 类型 |
|---|---|---|---|
| Baseline | 无控制,直接跟随负荷曲线 | 被动 | |
| RBC (rule-based controller) | 手工设定规则,例如“电价低时充电” | 基准控制 | |
| RLC (reinforcement learning controller) | SAC 算法自动学习策略 | 强化学习 |
1. Cost or Emission Reduction
以最小化电费成本或碳排放总量为KPI,进行三种方式的训练
1.1 实验设置
数据集: CityLearn Challenge 2023 (Phase 2 local evaluation)
建筑: 9 栋住宅
控制对象: DHW (热水储能) 或 BESS + PV (电池储能+光伏)
控制变量: 储能充放电功率
1.2 环境
Baseline – 不做任何控制。
RBC – 手动规则:
电价低 → 充能;
电价高 → 放能。
SAC – 深度强化学习自动学习最优调度
1.3 代码
from citylearn.citylearn import CityLearnEnv
from citylearn.agents.base import BaselineAgent
from citylearn.agents.rbc import BasicRBC
from citylearn.agents.sac import SAC
from pathlib import Path
def run(agent_class, schema, episodes=1, central_agent=True, save_dir=None, **kwargs):
print(f"\n=== Running {agent_class.__name__} ===")
env = CityLearnEnv(schema, central_agent=central_agent)
agent = agent_class(env)
agent.learn(episodes=episodes, deterministic_finish=True)
results = env.evaluate()
env.close()
print(f"✅ {agent_class.__name__} finished.")
if save_dir:
Path(save_dir).mkdir(parents=True, exist_ok=True)
(Path(save_dir)/"metrics.txt").write_text(str(results))
return results
def main():
# 使用本地数据集 schema
schema = "data/datasets/citylearn_challenge_2023_phase_2_local_evaluation/schema.json"
# 1 Baseline 无控制
res_base = run(BaselineAgent, schema, episodes=1, central_agent=True, save_dir="results/4_1_1_baseline")
# 2 RBC 规则控制
res_rbc = run(BasicRBC, schema, episodes=1, central_agent=True, save_dir="results/4_1_1_rbc")
# 3 SAC 强化学习控制
res_sac = run(SAC, schema, episodes=5, central_agent=False, save_dir="results/4_1_1_sac")
# 输出对比结果
print("\n=== Comparison ===")
print("Baseline:", res_base)
print("RBC:", res_rbc)
print("SAC:", res_sac)
if __name__ == "__main__":
main()目的是在相同环境下,依次运行三种控制策略(Baseline → RBC → SAC),并保存结果。主体是run函数,就详细讲他了
run函数是一个通用的实验运行函数,分为一下步骤
-
初始化环境
env = CityLearnEnv(schema, central_agent=central_agent)CityLearnEnv 是 CityLearn 的核心环境类,它根据 schema.json 读取城市能耗数据(建筑负荷、电价、太阳能、天气等)。
参数:
schema: 定义数据来源与环境配置(相当于一个配置文件路径)
central_agent: 是否为集中式控制(True 表示一个智能体控制所有建筑) -
初始化智能体
agent = agent_class(env)BaselineAgent:完全不做控制(仅被动执行环境动作)
BasicRBC:基于规则的控制(Rule-Based Control)
SAC:强化学习算法 Soft Actor-Critic 控制器 -
训练智能体
agent.learn(episodes=episodes, deterministic_finish=True)episodes:训练轮数(你给 Baseline/RBC 各 1 次,SAC 给 5 次)
deterministic_finish=True:在最后一个 episode 以确定性方式结束(用于评估) -
评估结果
results = env.evaluate()返回一个性能指标字典,如能耗、峰值负荷、碳排放、成本等
-
打印与保存
1.4 问题汇总
1.4.1 RBC(规则控制)的规则是什么?代码中怎么体现?
RBC(Rule-Based Control)是 基于人工经验规则的控制策略。在 CityLearn 中,RBC 主要负责控制每栋建筑的储能设备(电池)何时充电、何时放电。
默认规则如下:
当电价低(off-peak)时 → 充电
当电价高(peak)时 → 放电
若电池满或空 → 不动作
逻辑定义在city learn包的该文件中:citylearn/agents/rbc.py。简单的来说,就是一个if else而已
1.4.2. SAC(强化学习控制)用的是什么算法?
| SAC 是 Soft Actor-Critic)算法,基于最大熵强化学习(Maximum Entropy RL)的连续动作控制算法。就跟流程图中的一样,有三部分构成 | 模块 | 类型 | 功能 |
|---|---|---|---|
| Actor | 策略网络 | 生成动作分布 | |
| Critic₁ / Critic₂ | Q 网络 | 评估动作价值 | |
| Target Critic | 目标网络 | 稳定训练 |
1.4.3. RBC规则能否自定义
BasicRBC 是 CityLearn 自带的默认规则控制器(定义在 rbc.py)。但完全可以自定义自己的规则。只需继承基类并重写 select_actions()即可
例:
from citylearn.agents.base import BaseAgent
class MyRBC(BaseAgent):
def select_actions(self, observations):
actions = []
for obs in observations:
price = obs['electricity_price']
soc = obs['storage_soc']
solar = obs['solar_generation']
if price < 0.05 and solar > 0:
action = 1.0 # 加强充电
elif price > 0.2 or soc > 0.8:
action = -1.0 # 放电
else:
action = 0.0
actions.append(action)
return actions
run(MyRBC, schema, episodes=1, central_agent=True)1.4.4. SAC 强化学习控制是否和问题3一样?
也可以和问题3一样,自定义,只要实现相同接口即可
例:
from citylearn.agents.base import BaseAgent
from stable_baselines3 import PPO
class PPOAgent(BaseAgent):
def __init__(self, env):
super().__init__(env)
self.model = PPO('MlpPolicy', env, verbose=1)
def learn(self, episodes=1, **kwargs):
self.model.learn(total_timesteps=episodes * len(self.env.time_steps))
def select_actions(self, observations):
action, _ = self.model.predict(observations, deterministic=True)
return action
run(PPOAgent, schema, episodes=5, central_agent=False)ps:schema文件中reward_function配置(具体在2.2中解释)
"reward_function": {
"type": "citylearn.reward_function.RewardFunction",
"attributes": {
"electricity_cost_weight": 0.6,
"emission_weight": 0.4,
"peak_to_average_ratio_weight": 0.0
}
}2. Peak Reduction
以削减社区总功率峰值为KPI,进行三种方式的训练
2.1 环境
RBC 仍按规则上述运行
SAC 自动学会错峰操作——让各建筑在不同时间放电。
2.2 代码
4.1.2 节中明确指出,实验目标变为降低峰值负荷(district-level daily peak load)。文中说明:
“Configurations with peak reduction objective… The RBC has been fine-tuned to target energy discharge during peak periods…”
而在 CityLearn 环境中,KPI 由 reward_function 控制。所以要把 4.1.1 的“cost / emission minimization” 改成 4.1.2 的“peak reduction”,只需在 schema.json 里修改 reward 配置即可。
"reward_function": {
"type": "citylearn.reward_function.RewardFunction",
"attributes": {
"electricity_cost_weight": 0.0,
"emission_weight": 0.0,
"peak_to_average_ratio_weight": 1.0
}
}
其他代码与4.1.1相同
3. Discomfort and Electricity Consumption Reduction
KPI为在节能的同时维持舒适度(供暖、热水温度等)
3.1 代码
"reward_function": {
"type": "citylearn.reward_function.ComfortReward",
"attributes": {
"band": 1.0,
"lower_exponent": 2.0,
"higher_exponent": 3.0,
"m": 3.0,
"mode": "cooling"
}
}summary
| 在 4.1 部分的实验中,通过修改 schema.json 中的 reward_function 配置即可切换不同的性能评价指标(KPI)与控制目标,从而实现基于不同优化目标的策略训练 | 类名 | 所属模块 | 简要说明 | 可配参数(kwargs/attributes)示例 |
|---|---|---|---|---|
RewardFunction |
citylearn.reward_function |
默认通用奖励函数,惩罚从网格购买电力。 ([citylearn.net][1]) | exponent(如 1.0)、charging_constraint_penalty_coefficient 等 |
|
MARL |
citylearn.reward_function |
用于多体(multi-agent)场景的奖励函数 | 无或少量额外参数 | |
IndependentSACReward |
citylearn.reward_function |
推荐用于每建筑独立 agent 的 SAC 控制器奖励。 | 无或少量参数 | |
SolarPenaltyReward |
citylearn.reward_function |
鼓励净零/最大化自发电、减少从电网购电。 | 默认行为,无需额外参数或可配置参数如系数 | |
ComfortReward |
citylearn.reward_function |
以室内温度偏差(舒适度)为目标的奖励函数。 | band(舒适带宽)、lower_exponent、higher_exponent 等 |
|
SolarPenaltyAndComfortReward |
citylearn.reward_function |
结合太阳能惩罚 + 舒适度惩罚的混合型奖励。 | band、lower_exponent、higher_exponent、coefficients 等 |
所有的reward_function可以在这看:https://www.citylearn.net/api/citylearn.reward_function.html?utm_source=chatgpt.com
当然,以上仅针对SAC,如果是RBC,需要修改rbc.py文件里的策略,不过我觉得重点是SAC,所以暂且就先不管RBC的规则修改了
Energy storage system control in representative single-family neighborhoods
如果说4.1是多目标基准测试(环境固定,控制算法固定,KPI不同),那4.2就是不同建筑类型(如单层房、多层房、带太阳能的房屋)具有不同负荷特性与储能需求,同样的控制算法在这些“代表性住宅”上会表现出不同的能耗动态。
1. 重点
- 采用相同的 RL 控制策略(通常是 SAC);
- 在不同的 “representative neighborhoods” schema 上运行;
- 比较结果
· 电池充放电曲线 (SOC)
· 负荷曲线平滑程度
· 成本或碳排结果差异2. 区别
项目 4.1 部分 4.2 部分 实验主题 Benchmark 实验:在统一城市社区下测试不同 KPI(成本、碳排、峰值、舒适度) 应用实验:测试控制算法在代表性住宅社区的真实储能控制性能 实验目标(KPI) 切换不同 reward_function,比较不同优化目标 固定 reward(通常是 cost/emission),考察算法在不同建筑类型下的行为差异 控制结构 集中式或半集中式控制(central_agent 可 True) 分布式控制(central_agent=False,每栋建筑独立 agent) 环境规模 通常是完整城市或区域(多个住宅+商用建筑) 缩小到单家庭或少量代表性住宅群 重点分析 “不同 KPI 下的优化目标” “储能系统在现实住宅场景中的动态控制表现” 输出指标 reward 曲线、总能耗、PAR 每户建筑的电池 SOC 曲线、功率负荷、峰值变化趋势
3. 代码
和4.1其实大同小异,central_agent=False即可,突出各agent单独训练
# ============================================================
# CityLearn 4.2 实验复现: Energy storage system control
# 参考论文 Section 4.2
# ============================================================
from citylearn.citylearn import CityLearnEnv
from citylearn.agents.base import BaselineAgent
from citylearn.agents.rbc import BasicRBC
from citylearn.agents.sac import SAC
from pathlib import Path
from debug_sac import DebugSAC # ✅ 使用调试版本,不改库
# 测试用,仅使用n栋buildings
def run(agent_class, schema, episodes=1, central_agent=False, save_dir=None):
print(f"\n=== Running {agent_class.__name__} | Central Agent = {central_agent} ===")
# ✅ 正确选择前三栋建筑
env_full = CityLearnEnv(schema, central_agent=central_agent)
selected_buildings = env_full.buildings[:20]
env_full.close()
# ✅ 用3栋建筑创建新环境
env = CityLearnEnv(schema, buildings=selected_buildings, central_agent=central_agent)
env.reset()
agent = agent_class(env)
agent.learn(episodes=episodes, deterministic_finish=True)
results = env.evaluate()
env.close()
print(f"✅ {agent_class.__name__} finished.")
print(f"📊 Results: {results}")
if save_dir:
Path(save_dir).mkdir(parents=True, exist_ok=True)
(Path(save_dir) / "metrics.txt").write_text(str(results))
return results
# def run(agent_class, schema, episodes=1, central_agent=False, save_dir=None):
# print(f"\n=== Running {agent_class.__name__} | Central Agent = {central_agent} ===")
# # ✅ 创建环境
# env = CityLearnEnv(schema, buildings=env.buildings[:3], central_agent=False)
# # env = CityLearnEnv(schema, central_agent=central_agent)
# env.reset()
# # ✅ 创建 Agent
# agent = agent_class(env)
# # ✅ 训练 Agent(Baseline / RBC 会自动跳过 learn)
# agent.learn(episodes=episodes, deterministic_finish=True)
# # ✅ 评估指标
# results = env.evaluate()
# env.close()
# print(f"✅ {agent_class.__name__} finished.")
# print(f"📊 Results: {results}")
# # ✅ 保存结果
# if save_dir:
# Path(save_dir).mkdir(parents=True, exist_ok=True)
# (Path(save_dir) / "metrics.txt").write_text(str(results))
# return results
def main():
schema = "data/datasets/ca_alameda_county_neighborhood/schema.json"
central_agent = False
# Baseline
run(
agent_class=BaselineAgent,
schema=schema,
episodes=1,
central_agent=central_agent,
save_dir="results/4_2_baseline_CA"
)
# RBC
run(
agent_class=BasicRBC,
schema=schema,
episodes=1,
central_agent=central_agent,
save_dir="results/4_2_rbc_CA"
)
# SAC
run(
agent_class=DebugSAC,
schema=schema,
episodes=5,
central_agent=central_agent,
save_dir="results/4_2_sac_CA"
)
if __name__ == "__main__":
main()
4. 报错
4.1 AssertionError
AssertionError: demand is greater than heating_device max output | timestep: 0, building: resstock-amy2018-2021-release-1-122940, outage: False, demand: 3.1614, output: 2.9663, difference: 0.1950| CityLearn 在 building.py 里写了安全检查,类型如下 | 原因类型 | 说明 | 是否致命 |
|---|---|---|---|
| 1️⃣ 数据异常 | 某个住宅在输入数据(温度 / 负荷)首小时数值异常,使 heating_demand 超出设备额定功率 | ❌ 可跳过 | |
| 2️⃣ 模型初始化误差 | 在 simulation_start_time_step=0 时,系统状态还没初始化完全,出现轻微不一致 | ❌ 可忽略 | |
| 3️⃣ 温控模型精度问题 | HVAC 模型在某些时刻计算的 heat_demand 与设备参数有微小误差 | ❌ 可通过容差参数放宽 |
可以打开citylearn/building.py
查找并修改:
# before
assert self.power_outage or demand <= max_device_output or abs(demand - max_device_output) < TOLERANCE, \
f"demand is greater than heating_device max output | ..."
# now
if not (self.power_outage or demand <= max_device_output or abs(demand - max_device_output) < TOLERANCE):
print(f"[Warning] demand > heating_device max output at timestep {self.time_step}")或者跑代码的时候直接python -O run_4_2.py(忽略所有 assert 语句)
或者把容忍度从1e-4改大一些也行
TOLERANCE = 1e-4但是总体而言问题不大,论文里说了,在基于 ResStock 的建筑数据中,由于缩放差异,初始化时可能会出现轻微的设备容量超限,这不会影响实验结果。
4.2 TypeError: new(): data must be a sequence (got NoneType)
先看报错内容
(citylearnv2) root@autodl-container-491e4b9a34-9e5b11d5:~/CityLearn# python -O run_4_2.py
Couldn't import dot_parser, loading of dot files will not be possible.
=== Running SAC ===
Traceback (most recent call last):
File "/root/CityLearn/run_4_2.py", line 44, in <module>
main()
File "/root/CityLearn/run_4_2.py", line 40, in main
run(SAC, schema, episodes=5, central_agent=central_agent,
File "/root/CityLearn/run_4_2.py", line 16, in run
agent.learn(episodes=episodes, deterministic_finish=True)
File "/root/CityLearn/citylearn/agents/base.py", line 156, in learn
actions = self.predict(observations, deterministic=deterministic)
File "/root/CityLearn/citylearn/agents/sac.py", line 189, in predict
actions = self.get_post_exploration_prediction(observations, deterministic)
File "/root/CityLearn/citylearn/agents/sac.py", line 206, in get_post_exploration_prediction
o = torch.FloatTensor(o).unsqueeze(0).to(self.device)
TypeError: new(): data must be a sequence (got NoneType)常见成因如下
-
初始化观测没准备好
部分版本/数据(尤其 LSTM/ResStock 建筑)在创建后第一拍的观测可能为空:
· 没 reset()
· 或 reset() 返回完第一帧仍需要一个“热身 step”才有有效 obs -
schema 的观测被关了
如果 root.observations 里全都 "active": false,或某些建筑在buildings.*.inactive_observations 里把所有可观测量都禁用了,该建筑(甚至全局)观测会变成 None/空。 -
观测形态不匹配
central_agent=True → 期望得到“一个联合向量”;
central_agent=False → 期望“每栋一个向量的列表”。
如果有建筑 include: false / 观测被裁,列表里就会混入 None。
PS:太他妈变态了这个问题,这个error卡了我将近一周才知道哪里出现了问题
解决方法(过于变态,我选择讲我怎么解决的)
- 从数据集入手
可以运行一下这个代码,先查看building和obs里有没有none# inspect_schema.py import json, sys, argparse, os from typing import Any, Dict, List
def load_schema(path: str) -> Dict[str, Any]:
txt = open(path, 'r', encoding='utf-8').read()
先尝试 JSON
try:
data = json.loads(txt)
except Exception:
# 可选:YAML(若安装了 PyYAML)
try:
import yaml # pip install pyyaml
data = yaml.safe_load(txt)
except Exception as e:
print(f"❌ 既不是 JSON 也不是可解析的 YAML:{e}")
sys.exit(1)
# 大多数 CityLearn schema 顶层有个 'root'
return data.get('root', data)def main():
ap = argparse.ArgumentParser()
ap.add_argument('--schema', required=True, help='path/to/schema.json')
args = ap.parse_args()
sc = load_schema(args.schema)
print("\n=== Top-level keys ===")
print(list(sc.keys()))
# 1) central_agent & sim period
print("\n=== Simulation/Agent ===")
print("central_agent:", sc.get('central_agent'))
print("simulation_start_time_step:", sc.get('simulation_start_time_step'))
print("simulation_end_time_step:", sc.get('simulation_end_time_step'))
print("seconds_per_time_step:", sc.get('seconds_per_time_step'))
# 2) observations(全局)
obs = sc.get('observations', {})
print("\n=== Global Observations ===")
if not obs:
print("⚠️ observations 是空的(这会导致 SAC 观测为 None)")
else:
actives = [k for k,v in obs.items() if isinstance(v, dict) and v.get('active', False)]
inactives = [k for k,v in obs.items() if isinstance(v, dict) and not v.get('active', False)]
print("active 数量:", len(actives))
print("active 列表(前20):", actives[:20])
if inactives:
print("inactive 列表(前20):", inactives[:20])
# 3) buildings(字典或列表)
b = sc.get('buildings', {})
print("\n=== Buildings ===")
if isinstance(b, dict):
b_names = list(b.keys())
print("建筑数量:", len(b_names))
sample = b_names[:5]
print("示例建筑:", sample)
# 检查 include / inactive_observations
problem_buildings: List[str] = []
fully_inactive: List[str] = []
for name in b_names:
cfg = b[name] or {}
include = cfg.get('include', True)
if not include:
problem_buildings.append(name)
inact = cfg.get('inactive_observations', [])
# 如果把全局 active 都屏蔽了,也会导致该建筑 obs=None
try:
actives = [k for k,v in obs.items() if isinstance(v, dict) and v.get('active', False)]
if actives and isinstance(inact, list) and set(inact) >= set(actives):
fully_inactive.append(name)
except Exception:
pass
if problem_buildings:
print(f"⚠️ 有 {len(problem_buildings)} 栋建筑 include=false(可能导致 None):", problem_buildings[:5])
if fully_inactive:
print(f"⚠️ 有 {len(fully_inactive)} 栋建筑把所有全局观测都屏蔽了:", fully_inactive[:5])
else:
print("⚠️ buildings 不是字典(请贴内容我再看)")
# 4) 快速“环境探针”(不训练,只 reset 看看 obs 形态)
try:
from citylearn.citylearn import CityLearnEnv
ca = sc.get('central_agent', False)
print("\n=== Env probe (reset) ===")
env = CityLearnEnv(args.schema, central_agent=ca)
obs0 = env.reset()
print("reset() 返回类型:", type(obs0))
if obs0 is None:
print("❌ reset() 返回 None —— SAC 会在 FloatTensor(None) 处报错。")
else:
try:
# centralized → 向量/数组;decentralized → list[数组]
if isinstance(obs0, list):
shapes = [getattr(x, 'shape', None) for x in obs0]
print("分布式观测数量:", len(obs0), "示例形状:", shapes[:5])
else:
print("集中式观测形状:", getattr(obs0, 'shape', None))
except Exception:
pass
env.close()
except Exception as e:
print("(可选探针失败:)", e)if name == 'main':
main()
我的运行结果
1. 进行调试
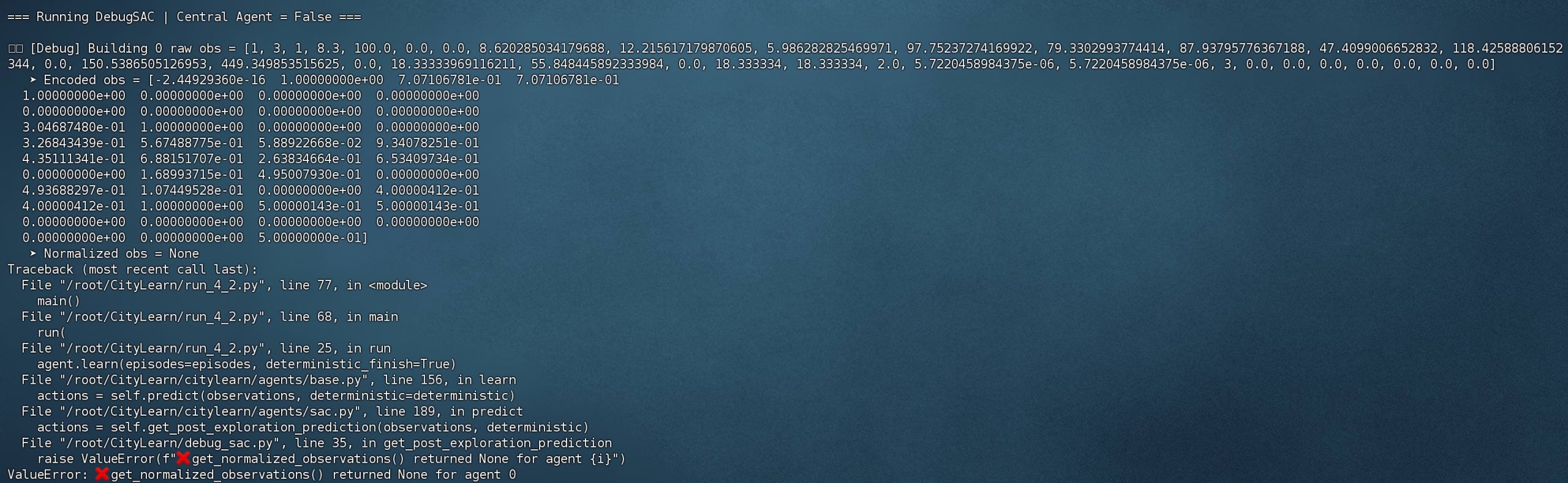
从报错中可以知道,问题主要是出现在sac.py的self.get_post_exploration_prediction里,再建一个py文件重写该类,查看到底是哪一步出现了问题import numpy as np
import torch
from citylearn.agents.sac import SAC
class DebugSAC(SAC):
"""调试用 SAC:不改原库,但打印 observation & None 来源"""
def get_post_exploration_prediction(self, observations, deterministic=False):
# ✅ 如果是 dict,先转换为 list,避免原始错误
if isinstance(observations, dict):
observations = [obs for obs in observations.values()]
actions = []
for i, o in enumerate(observations):
# ✅ Debug:打印原始 obs
print(f"\n🔍 [Debug] Building {i} raw obs = {o}")
if o is None:
raise ValueError(f"❌ Observation from agent {i} is None (raw environment output)")
# ✅ 编码
encoded = self.get_encoded_observations(i, o)
print(f" ➤ Encoded obs = {encoded}")
if encoded is None:
raise ValueError(f"❌ get_encoded_observations() returned None for agent {i}")
# ✅ 归一化
normalized = self.get_normalized_observations(i, encoded)
print(f" ➤ Normalized obs = {normalized}")
if normalized is None:
raise ValueError(f"❌ get_normalized_observations() returned None for agent {i}")
# ✅ 尝试转成 tensor
try:
o_tensor = torch.FloatTensor(normalized).unsqueeze(0).to(self.device)
except Exception as e:
print(f"❌ Failed to convert obs to tensor. Obs = {normalized}")
raise e
# ✅ 原来的 action 获取流程
result = self.policy_net[i].sample(o_tensor)
a = result[2] if deterministic else result[0]
actions.append(a.detach().cpu().numpy()[0])
return actions把步骤分开,终于!找到了问题所在--normalized,为什么会有这个问题呢?
**reason:**
CityLearn SAC 中归一化机制没有被初始化 / 未启用或遇到了无效值,所以 get_normalized_observations() 返回了 None → 传给 torch.FloatTensor() → 报错
这是 CityLearn SAC 框架的一个“设计缺陷”(默认不开启 normalization,又没有 fallback 机制)
citylearn的默认流程是这样的:
1. normalization_enable 默认是 True
2. 但 normalization 参数(mean/std)只会在训练若干步后才更新
3. 第 1 个 timestep 直接调用 predict() → normalization 矩阵还没有 → 返回 None
**soluation**
归一化在SAC中还是需要的,不然会难以收敛或不稳定,而且不能修改schema里的数据(json里保存的都是真实原始数据)
两种方法
1. 在训练前自动收集数据,初始化 mean/std
初始化 normalization
obs_buffer = []
obs = env.reset()
for _ in range(500): # 收集前 500 步
action = env.actionspace.sample() # 随机动作
obs, , , = env.step(action)
obs_list = list(obs.values()) if isinstance(obs, dict) else obs
obs_buffer.extend(obs_list)
obs_buffer = np.array(obs_buffer)
agent.obs_mean = np.mean(obs_buffer, axis=0)
agent.obs_std = np.std(obs_buffer, axis=0) + 1e-6 # 避免除0
print("✅ Normalization initialized.")
2. 中途动态归一化
在 SAC 内部每收集一批数据就更新 mean/std(类似 running mean),只需训练前手动运行几步 env.step() + agent.observe() 即可。
## summary
4.1 是算法在不同 KPI 下的“目标函数对比实验”;
4.2 是同一算法在不同住宅场景下的“实际储能控制实验”。
针对TypeError: new()::
在 CityLearn + SAC 中,归一化之所以会出现 None 并报错,是因为强化学习里的智能体(agent)是通过与环境逐步交互来“学习观察数据的分布”,而不是像传统机器学习那样在一开始就加载所有数据并计算整体均值和标准差。归一化需要用到观测数据的均值和标准差(mean/std),但在训练初期,agent 还没有收集到足够的观测数据,这些归一化参数尚未建立,因此 get_normalized_observations() 返回了 None。也就是说,错误并不是由原始数据或环境造成的,而是因为“agent 还不了解环境的数据分布,却提前尝试对整个环境进行归一化”。解决方法可以是跳过归一化、在训练前进行 warm-up 收集数据以初始化均值和标准差,或使用 centralized agent 等方式。
# Vehicle-to-Grid Control
## 1. 重点与目标
在 CityLearn 环境中扩展强化学习模型,使得电动汽车不仅能充电,还能在高峰时段将电能回馈给建筑或电网,以实现削峰填谷和整体能耗优化,目标如下
1. 将 V2G 机制引入智能电网中的多建筑控制框架;
2. 探究 RL 智能体如何在建筑储能系统与电动汽车电池之间协调能量流动;
3. 目标函数不仅考虑电费最小化,还考虑排放、峰值负荷和舒适度约束。
## 2. 环境设置
在 CityLearn 环境中,每栋建筑不仅有battery储能系统,还额外配置EV battery,RL 智能体的动作空间包括:
```math
a_t = \left[ a_{\text{building battery}},\ a_{\text{EV battery}} \right]其中每个a_t
- EV 的可用时间窗口由住宅用户行为数据确定(车辆通常白天离家、夜晚接入电网);
- 充电功率受限于
P_{\max} - 动作经过归一化与裁剪,保证物理可行性。
3. 奖励函数
典型形式为:
r_t = -\alpha C_t - \beta E_t - \gamma P_{\text{peak},t}where
C_tE_tP_{\text{peak},t}\alpha, \beta, \gamma
通过 V2G,智能体学会在高价时段放电、低价时段充电,从而降低综合成本。
4. 区别
| 对比项 | 4.1 Baseline Control (RBC/Baseline) | 4.2 Reinforcement Learning Control (SAC) | 4.3 Vehicle-to-Grid Control (V2G) |
|---|---|---|---|
| 控制对象 | 仅建筑电池 (Building Battery) | 同上 | 建筑电池 + 电动车电池 (Building + EV Battery) |
| schema 文件 | schema.json(基础建筑) |
schema.json(相同) |
v2g_schema.json 或带 include_ev=True |
| 动作空间 | ( at = [a{\text{building}}] ) | 同上 | ( at = [a{\text{building}}, a_{\text{EV}}] ) |
| 状态空间 | 建筑电负荷、太阳能、SoC、电价等 | 同上 | 额外包含 EV SoC、EV 可用时间窗口 |
| 强化学习智能体 | 无(规则控制) | SAC / PPO | SAC(支持 EV 充放电调度) |
| 目标函数 | 最小化电费 | 同上 | 最小化电费 + 排放 + 峰值功率(多目标) |
| 新参数 | — | — | v2g=True 或 include_ev=True |
| 仿真特点 | 单能系统 | 单能系统 + RL 控制 | 多能系统(建筑 + 车辆 + 电网) |
| 创新点 | 传统控制基线 | RL 适应性学习 | RL 扩展到双储能协同优化 |
一句话概括就是,4.3在RL基础上进一步扩展到“建筑 + 电动车”双储能控制,即 Vehicle-to-Grid (V2G)
5. 代码
以4.1的SAC部分为baseline,如下
from citylearn.citylearn import CityLearnEnv
from citylearn.agents.sac import SAC
from pathlib import Path
def run_v2g(agent_class, schema, episodes=3, central_agent=False, save_dir=None, **kwargs):
print(f"\n=== Running {agent_class.__name__} (Vehicle-to-Grid) ===")
# ✅ 启用 include_evs / v2g 参数
env = CityLearnEnv(schema, central_agent=central_agent, include_evs=True, **kwargs)
agent = agent_class(env)
agent.learn(episodes=episodes, deterministic_finish=True)
results = env.evaluate()
env.close()
print(f"✅ {agent_class.__name__} (V2G) finished.")
if save_dir:
Path(save_dir).mkdir(parents=True, exist_ok=True)
(Path(save_dir)/"metrics.txt").write_text(str(results))
return results
def main():
# ✅ 使用含 EV battery 的 V2G 版本 schema
schema_v2g = "data/citylearn_challenge_2022/v2g_schema.json"
# ✅ 运行 SAC 控制器(Vehicle-to-Grid 实验)
res_v2g = run_v2g(SAC, schema_v2g, episodes=5, central_agent=False, save_dir="results/4_3_v2g_sac")
print("\n=== V2G SAC Results ===")
print(res_v2g)
if __name__ == "__main__":
main()Occupant comfort feedback during automated demand response
貌似复现不出来,因为这是一个基于CityLearn的EULP数据 + Ecobee DYD 的真实用户统计模型,
构建出的半实数据仿真案例(semi-synthetic simulation)。
1. 目的
研究在自动化需量响应(Automated Demand Response, ADR)期间引入住户舒适度反馈机制对整体电力负载与控制性能的影响。
通过引入住户覆盖(override)模型,模拟当用户感到不舒适时回退恒温器设定温度的行为,同时对比不同层次的住户建模复杂度(Level of Detail, LoD 1–3)对能源成本、峰值负载削减以及住户不适次数的影响
环境配置
| 模块 | 配置 / 说明 |
|---|---|
| CityLearn 版本 | 2.4.2(或 ≥ 2.4) |
| Python 版本 | 3.10+ |
| 强化学习算法 | Soft Actor–Critic (SAC) |
| 硬件环境 | Ubuntu/macOS, CPU / GPU 可选 |
| 基础数据集 | EULP(Electric Utility Load Profiles, Montréal 冬季) |
| 住户行为模型 | Ecobee Donate Your Data(DYD)数据训练出的覆盖概率模型 |
| 仿真周期 | 冬季三个月(12月–2月) |
| 建筑数量 | 10 栋独立住宅 |
| 仿真粒度 | 1小时步长(24×90 steps) |
| DR事件 | 工作日18:00–21:00设定点下调 1.1°C (≈2°F) |
| 对照组 | LoD1: 基线,无控制;LoD2: ±2°C舒适带,RL控制;LoD3: ±2°C+覆盖模型+DR事件 |
| 输出指标 | 电费成本、峰值功率、总耗电量、覆盖次数与覆盖幅度 |
对比
| 项目 | 4.1 Basic Control | 4.2 Community Coordination | 4.3 Multi-Objective (Economic/Emission) | 4.4 Comfort Feedback (本节) |
|---|---|---|---|---|
| 研究重点 | 单建筑基本负载控制 | 多建筑间能量协调 | 多目标权衡(成本 vs 排放) | 住户舒适反馈与DR响应 |
| 数据集 | 简化住宅负载 | 社区级EULP | 同上 | 同上(+ DYD行为模型) |
| 控制目标 | 成本最小化 | 成本 + 负载平衡 | 成本 + 排放 | 成本 + 舒适度(减少覆盖次数) |
| 外部信号 | 电价 | 电价 | 电价 + 排放因子 | 电价 + DR事件 |
| 住户模型 | 固定设定温度 | 固定设定温度 | 固定设定温度 | 动态设定温度 + 覆盖行为 |
| LoD (复杂度) | LoD1 | LoD1–2 | LoD1–2 | LoD1–3 |
| 强化学习结构 | 单智能体 SAC | 多智能体 SAC | 多目标 SAC (Reward = αCost + βEmission) | 多目标 SAC (Reward = αCost + βComfort) |
| 评价指标 | 能耗/成本 | 能耗/峰值 | 成本+排放指标 | 成本+峰值+覆盖次数 |
总结来说,4.4在4.3基础上加入人的因素(住户舒适反馈)